
 Edit on GitHub
Edit on GitHub「この微妙な違いって何?」を画像AIで解決!曖昧さを分類するAIソリューションはじめました (解説編)
「この微妙な違いって何?」を画像AIで解決!曖昧さを分類するAIソリューションはじめました (解説編)
ソフトバンクではAIプロフェッショナルサービスを展開しておりますが、「一体どういった事を解決してくれるのか?」についてはお問い合せいただかないと中々お応えする機会がありませんでした。 そこで本記事では、AIプロフェッションサービスの中でも特に画像領域では一体どういった事をやっているのか?、その一部をチラ見せできればと思います。
https://www.softbank.jp/biz/services/platform/alibabacloud/about/ps/
※ テックブログとしての投稿ですが、本サービスの一部ソリューションを概要レベルで掴んでいただくための構成となっており、技術のより深いところまでは解説しておりません。(技術技術していなくすいません。)
1. はじめに
1.1. 概要:目を酷使する作業からの解放宣言!!
本記事の概要は以下の通りです。"ざっくり" 何をしたいかが伝われば幸いです。
- Problem ) "ごちゃっとした・複雑で・細かな・違い"を見分けるの(識別・判別)っていろいろと大変
- 長時間労働 : どうしても目が疲れちゃうし長時間は無理!!(集中するにしても…1日数時間が人間の限界?休憩も必要)
- 判断の曖昧さ: 人をたくさん雇っても、人それぞれ判断基準が曖昧になってくるし、判別精度もまちまちに…
- 育成プロセス: 新規で雇ってエキスパートレベルになるまで教育・経験を積むにしても、それなりに時間も掛かる - Suggestion ) ある程度のところまでAIがサポートしてくれると、人間はすごく幸せになれるのでは?
- なんとAIプロフェッショナルサービスではその解決策を提案しています!
- ある程度のところまでAIが判断し、"曖昧さ"が残る部分だけを人間がチェックすればよい
- 顔認識・顔認証の分野で研究が進んでいる技術を応用しているため、今後も継続的な技術進化が望めます♬ - Give it a TRY! ) ずぶの素人が専門家に太刀打ちできるのか?やってみた〜蝶編〜
- Conclusion ) [AIプロフェッショナルサービス]で一緒に幸せになりましょう♫
- 本技術がお役に立てそうなお困り事がございましたら是非ご協力させてください!
1.2. 必見:こんな方に読んでほしい
本記事は、以下のようなご興味をお持ちの方を対象にしてます。
- 「AIプロフェッショナルサービスって一体何やってるの?」を垣間見たい方
- 技術軸またはビジネス軸において、本サービスにご興味のある方
- 特に画像はまだ無いけど、もしも使えそうならシーンがありそうなら是非利用してみたいとお考えの方
- とにかく画像は大量にあるから、利用シナリオについてどんな事ができそうかご相談してみたい方
- 既に上記 Problem を抱えている方
- "判別、識別、分別、区別、弁別、仕分け"といった作業をしていて、日々大変さ・辛さを感じている方
- 長時間、目を酷使した仕事・業務を抱えていて、何かしら解決の緒を見つけたい方 - 細かい違い・微妙な差のある画像を大量に持っている方で、「この違いって何?」にご興味のある方
- ざっくり "AI、Computer Vision、Deep Learning、画像認識、画像識別、画像認証、etc..." にご興味のある方
[AIプロフェッショナルサービス]でどんな課題を解く事ができるのか、本記事を通してイメージしていただけたらミッション・コンプリートです。
さて、ここまでお読みいただいて「なんだなんだ?」とご興味が湧きましたら、続きをどうぞ!
2. 違いの分かりづらい分類へのアプローチ〜理論編〜
本章ではアプローチ方法について軽く解説します。「技術的な話より実例が見たい!」という方は、本章はスキップしてください。
2.1. アーキテクチャ/アルゴリズム
分類ロジックとしては顔認識・顔認証の分野で研究が進んでいる技術を応用しています。この分野は「大量にある顔の中で "同じ顔だ"(すなわち、同一人物だ) と正しく判断する」事を目標に掲げ、顔ひとつひとつの細かな違いを識別するためのアーキテクチャ/アルゴリズムが日々刻々と研究されています。
Article: Deep Face Recognition: A Survey

本ソリューションの実際の詳細な中身については企業秘密となりますが、どういった事をしているのかをふわっと解説すると、各データ(顔画像)を高次元空間にマッピングする事を考えます。具体的には以下のステップを踏む事です。
- 各顔画像から「顔の特徴情報」を抽出 :Feature Extraction
- 抽出した特徴情報を高次元空間にプロット :Feature Plotting
- プロットする際は、以下の条件を満たすようにマッピングを学習 :Train Mapping/Surjection
- 激似の人(ドッペルゲンガー) :ほぼ同じ点にプロット
- まあまあ似ている人(そっくりさん) :ある程度近くにプロット
- 全くの別人 :できるだけ遠くにプロット
ここで重要なポイントは「マッピングをうまく学習させる」という部分です。
下図は顔画像をひとつひとつ3次元空間へプロットしたものと捉えてください。プロットされた1点1点が顔画像を表し、同じ色(例えば青色の点群)は同一人物を表しています。6色あるので6人分の顔をこのプロット空間を基に判別しようとしていると考えてください。

ここで "顔画像" と言っても、正面の顔やうつむき顔、横顔、笑顔、泣き顔、驚き顔など、撮影する向きや表情によって多種多様ありますよね。あるいは夜野外で撮影したもの、室内で撮影したもの、撮影環境もいろいろあります。ですので同一人物の顔画像であってもある程度散らばってプロットされるのはなんとなく理解できます。
この時、「マッピングをうまく学習させる」とはどういう事か?下図を基に説明すると
- ・左図にいくほどばらけてプロットされており、他人との判断境界が曖昧になっていく
- ・右図へいくほど局所的なプロットへおさまっており、同一人物かの判断がしやすくなる
「マッピングをうまく学習させる」というのは、例え何十億人もの顔画像が与えられたとしても、より右図へ近づけるようにマッピング(写像)自体を適切に学習させる事、さらに遡るとそれを成し得る質の良い「顔の特徴情報」を得られるよう抽出方法自体も改善していく事を意味します。これらが可能になる事で、近くにプロットされれば本人、もしくはそっくりさんだと判断できるし、遠くにプロットされれば赤の他人だと判断できるようになる、というのが理屈です。
SphereFace: Deep Hypersphere Embedding for Face Recognition

「同じものかどうか?」、差が見分けづらい大量の画像に対して、いかにマッピングを適切に学習させられるかが[AIプロフェッショナルサービス]の見せどころという事になります。例えば顔認識・顔認証の分野では以下がポイントです。
- ・同一人物であっても撮影条件の違いや表情の違いが出てくるが、マッピングする時にそれらをどう吸収するか
- ・そっくりさんであってもちゃんと「本人 / 他人」の区別が正しくできるようになっているか
つまりこの分野の技術進化が「細かい違い・微妙な差のある画像をいかに正しく区別するか」の成功の鍵ともいえます。
2.2. 強力なメソッド:可視化

前述の通り、マッピングをうまく学習させる事で「似ている / 似ていない」の判断を可視化できるという事になります。これは「違いの分かりづらい画像の分類」作業においてとても強力なメソッドだといえます。 前章での説明の際に用いた可視化(3次元空間へのプロット)について、例えば以下のような活用が想定できます。
2.2.1. 新人向け教育ツール:作業効率化
何かしらの仕分け作業を新人さんにやらせたい時、「ここの境界部分は怪しいから集中的に注意深くチェックして」「ここら辺は違いがはっきりと分かれてるから後回しでいいよ」等と指示ができます。例え経験値がない新人さんでも、ある程度効率的に作業を進める事ができるようになります。
また可視化によって判断基準を定め、作業する人の間での共通認識を持つ事が可能になるという事は「あの時どうしてこう判断したか?」のエビデンスとしても活用する事ができます。
2.2.2. 違いへの探求:気づき、発見
2.2.2.1. 探求への入り口
「この違いって何?」が気になっている微妙な差のある画像をお持ちだとします。あるいは分類してみたいけどどう分けたら良いか、何カテゴリーに分けるのが正しいのか、悩んでいる画像があるとします。そういった時は本ソリューションでまず可視化してみましょう。
点群がいくつかの塊(グループ)に分かれればそこを分類の基準にしてみてはいかがでしょうか。つまり塊の数だけカテゴリーに分けてみるとよいでしょう。さらには同じ塊(グループ)の中の画像をいくつか見てみてください。その境界/中心部分ではどこが変化していくのか、あるいは変化しないのか、「細かい違い / 微妙な差」を理解するのに是非お役立てください。
2.2.2.2. 経年変化への対応
下図は元々 "3種類" の違いを分類していたものを可視化しています。

どうでしょうか。茶色の点群はさらに3つの塊(グループ)に分けられそうですね。 つまり可視化してみる事で今まで認識していなかった新たな分け方に気づく事ができるかもしれません。 あるいは今までひとまとまりに分類していても問題なかったところへ、時間の経過と共に新種・亜種(ノイズ)が出てきたと気づく事ができるかもしれません。
3. やってみた:挑戦!AIで素人はどこまで専門家に近づけるか〜実践編〜
それでは実際に画像のデータセットを用意して試してみます。
3.1. データセット、画像
今回はCC0-1.0ライセンスの画像で、かつ、素人では見分けるのが難しい(時間を掛けて鍛錬すればもしかしたらできるかもしれないが、相当面倒クサい…)領域の画像として、蝶の標本データ(画像)を用いて"ざっくり"分類をしてみます。 つまり、「昆虫学に精通していなくても、画像AIを用いてどこまで分類することが可能か」を試していく事になります。
画像データの取得条件は以下の通りです。

3.2. Let's 学習!!
学習用画像が用意されている『クモマツマキチョウ/エゾシロチョウ/オオモンシロチョウ』の3種についてマッピングをうまく学習させてみます。 学習時に与えるのは「画像そのものとそれがどの種か(学名)」の情報のみです(つまり、<Image, Label> のペア)。 なぜなら今回は「個体識別」をしたいというよりも、その蝶が「どの種類か」を判断したいので、同じ種に属する蝶を同じ学名グループとして学習していきます。
3.2.1. 全体
さて、結果は以下のようになりました。同色であるプロット1点1点は学習用として用意した約160枚/種の画像を表しています。
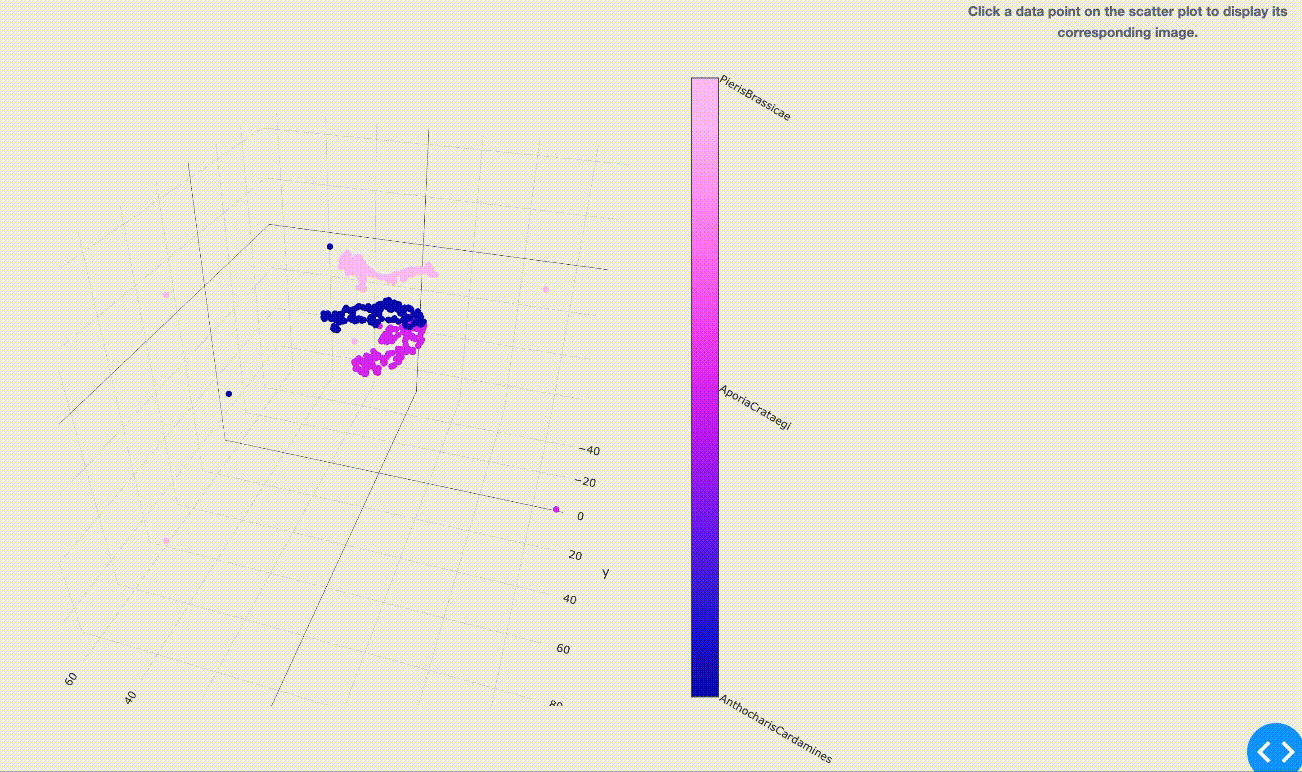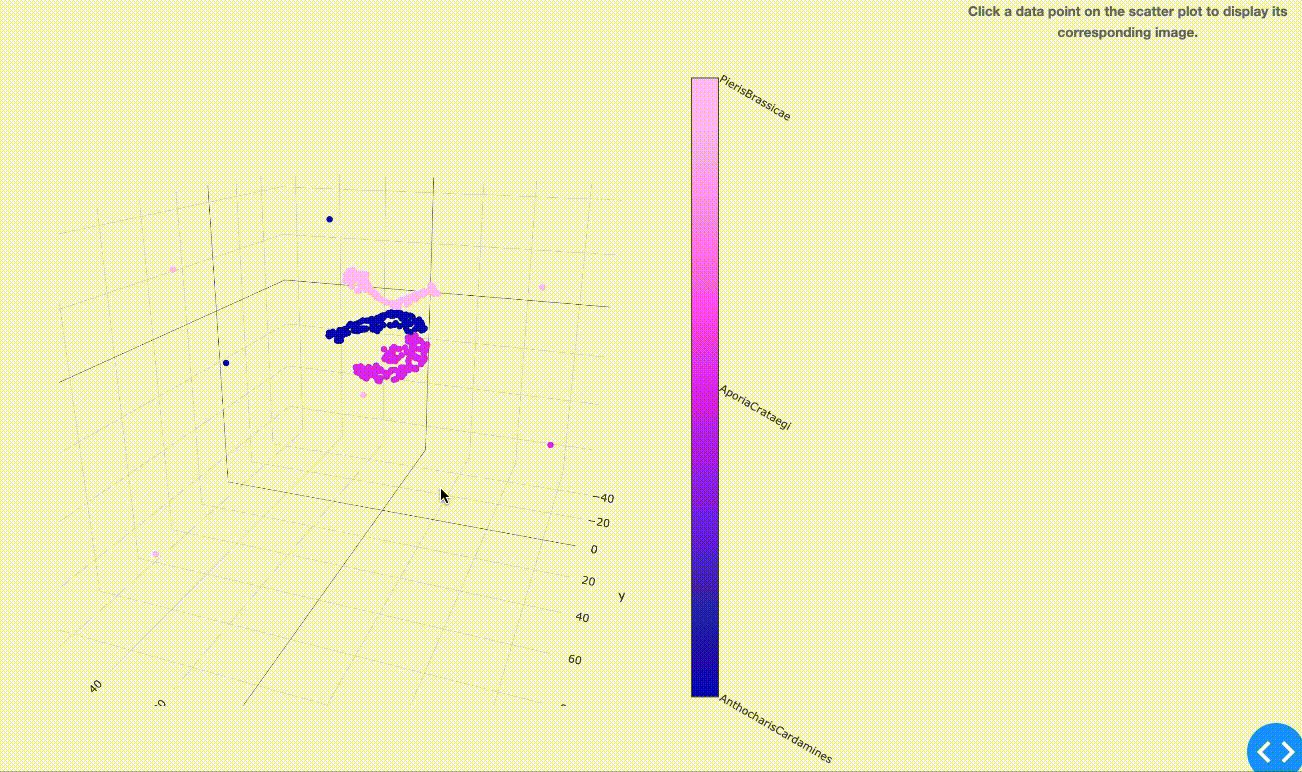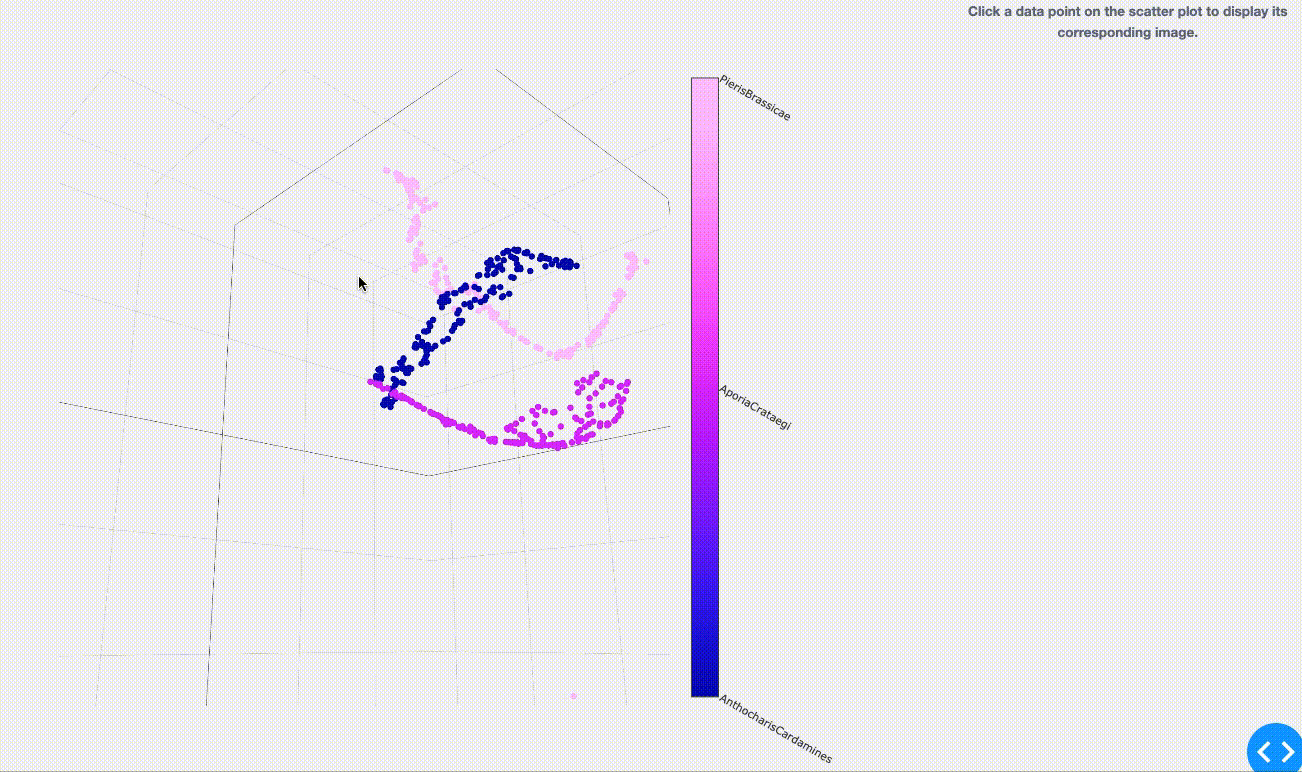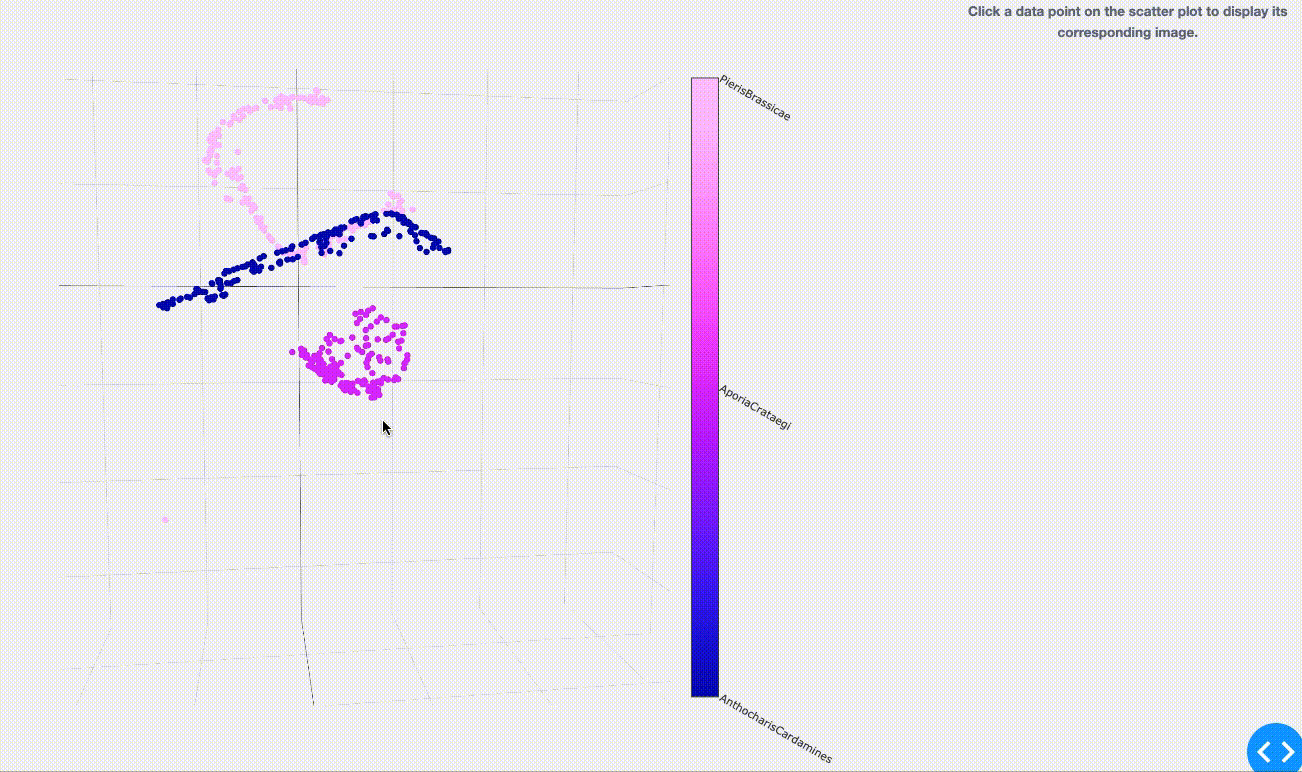
( 2.1でご紹介した図とは一見異なる表現のように思えるかも知れませんが、元々は高次元空間のモノを3次元空間へ次元を落として表現しているので、上図のように各点群がごちゃっと入りくんだ状態になります。)
学習の時点で同種の蝶(同色の点)は群がってプロットされている事がわかります。 しかし点群からはみ出しているものや、境界が曖昧な箇所へプロットされてしまっているものも一部ありますね。 今回は時間があまり取れなかった為に、学習時のチューニングをしっかりできていないのが原因の一つかもしれません…(今回は数日程度を学習に使いました)。 もしくは、実際に他の同種画像とはちょっと違いのある画像(つまり新種の発見 or 亜種の紛れ込み?)、または他種の方に似ている画像(つまり分類ミスの発見?)なのかもしれません。 まさに違いの探求への入り口が垣間見えましたね。
3.2.2. 1点1点のプロット
実際に点をクリックで選択してみると次の情報が得られます。

- category : 選択画像のラベル情報。ここでは「学名」をラベルとして扱っており、選択画像がどの学名(種)に属しているのかを表す。
- threshold: 各種の点群(つまり各色のグループ)ごとのまとまり具合の閾値。 \- つまりテストしたい点(画像)がこのまとまりの中に含まれれば「同種」だと判断し、まとまりからはみ出していれば「他種」だと判断ができる。 \- 逆に言うと、学習の時点で十分な数のデータ(画像数)を用意できなければこのまとまり具合の精度が下がり、テスト結果へも影響が出ることになります。
1つずつプロットされた点を見ていく事によって、似たような画像が近くにプロットされている事が体感できますね。
また点群から外れている点(画像)がどういったものなのかも確認できますね。
3.3. Let's テスト!!
それではテスト用に取得しておいた画像をプロットしてみましょう。
3.3.1. 全体
さて、結果は以下のようになりました。同色であるプロット1点1点はテスト用として用意した(学習用には含まれていない)約30枚/種の画像を表しています。
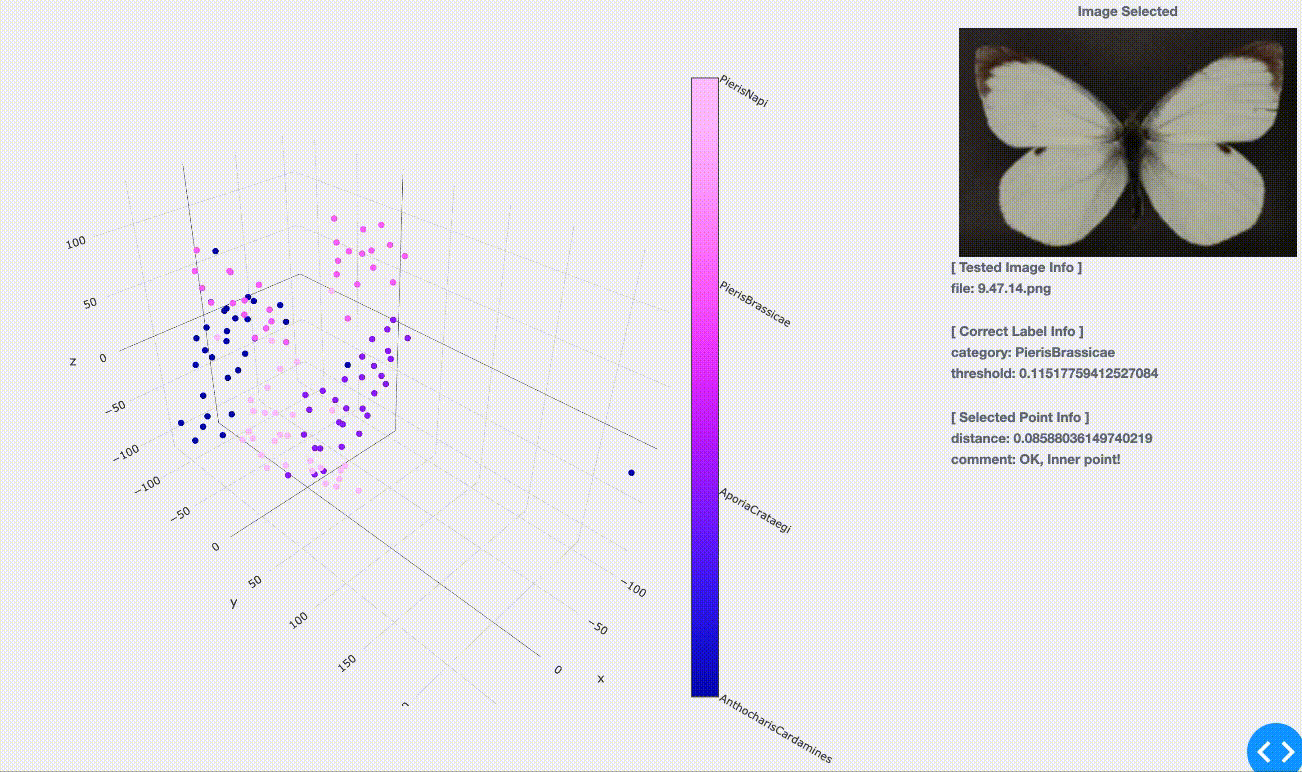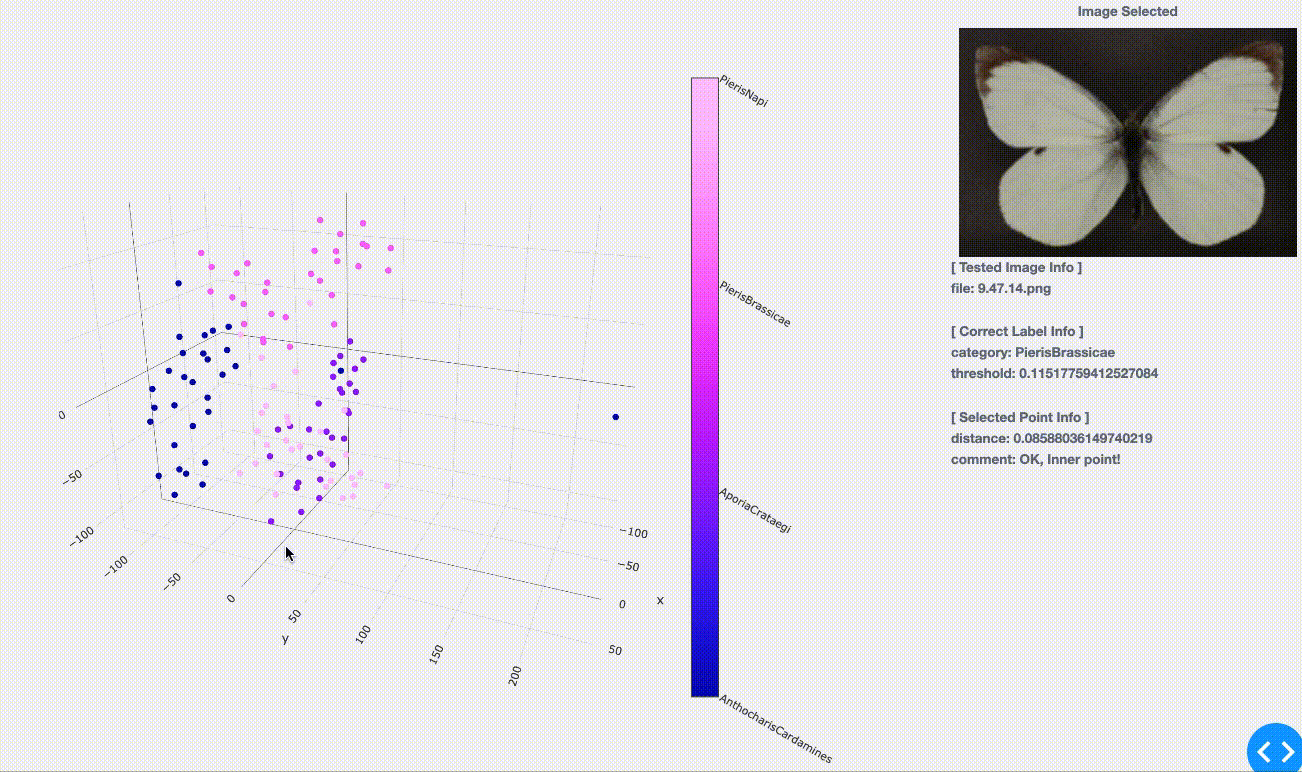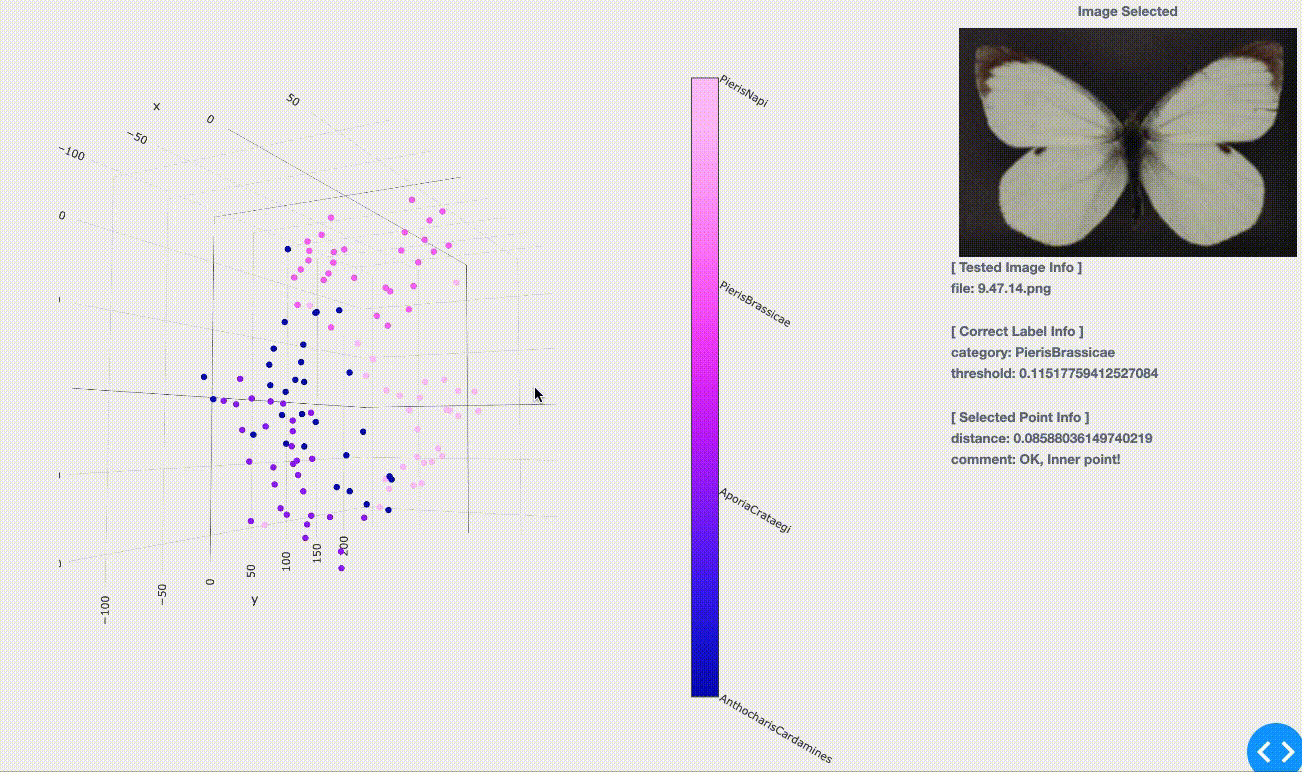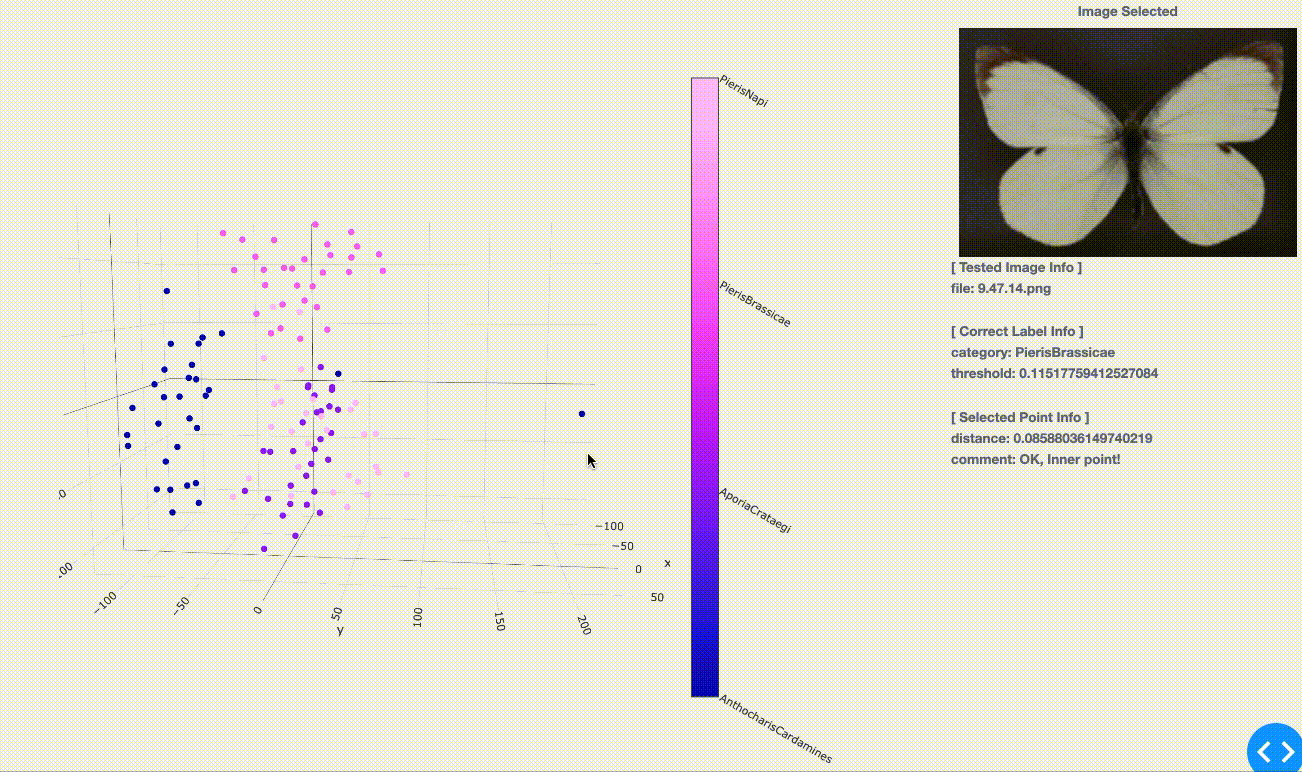
( 学習編とは見た感触が違うように感じられるかもしれませんが、こちらには学習用点群(プロット、約160枚/種)を含めず、テスト用のみをプロットしているためです。)
(学習用に投入していない)初見のテスト画像に対してある程度まとまってプロットされている事が見てとれます。 学習の時点では同種の蝶(同色の点)は群がってプロットされていましたが、そこで「マッピングをうまく学習させられた」事による成果ですね。つまり、「同種に似ているから近くへプロットしようっと!」という事をうまく学んでくれたのです。
3.3.2. 未知への対応力
さて、上図で何か気づきませんでしたでしょうか?
- ・事前に学習している3種 :クモマツマキチョウ(青)/エゾシロチョウ(紫)/オオモンシロチョウ(ピンク)
- ・学習すら行なっていない未知の1種 :エゾスジグロシロチョウ(薄ピンク)
学習済みの3種についてはもちろん塊ができていますが、学習にすら掛けていない未知である1種についてもなんとなく塊ができているように見えます。 これは、すごい👏👏👏👏 既に学習した知識を基に、「青にも似てないし紫にも似てない。ピンクにも…。あ!!でも特徴情報を抽出してプロットしてみたら同じところに行きそうだぞ!?」という事が内部で起きているとか起きていないとか。
これは、新種・亜種が出てきてもある程度柔軟に対応する力がある事を示唆しています。
3.3.3. 1点1点のプロット
実際に点をクリックで選択してみると次の情報が得られます。

[Correct Label Info]:正解の分類情報、学習時と同様
- category : 選択画像のラベル情報。ここでは「学名」をラベルとして扱っており、選択画像がどの学名(種)に属しているのかを表す。
- threshold: 各種の点群(つまり各色のグループ)ごとのまとまり具合の閾値。 \- つまりテストしたい点(画像)がこのまとまりの中に含まれれば「同種」だと判断し、まとまりからはみ出していれば「他種」だと判断ができる。 \- 逆に言うと、学習の時点で十分な数のデータ(画像数)を用意できなければこのまとまり具合の精度が下がり、テスト結果へも影響が出ることになります。
[Selected Point Info]:学習済みの点群を基にした、クリック点に関する情報
- distance :一番近い点群までの距離
- comment :学習済みの点群に含まれるかどうか \- OK, Inner point! :確実に含まれる=同種 \- NG, Above threshold :含まれるけど閾値ギリギリ⇨要チェックポイント \- NG, Outlier point... :含まれない=外れ値。亜種か、別種が紛れている可能性。
threshold(閾値)によって境界が曖昧なものを判断しています。この値に応じて、要チェックなのか、プライオリティを上げるべきか、作業の基準とする事ができます。
注意点としては、下図には今回学習時の点群が含まれてませんので、一見するとピンクの点群が二つの塊(グループ)に分けられそうだったり、青で外れ値のように見える点があっても、学習用の点群とオーバラップさせると塊(グループ)に含まれている(つまり、OK, Inner point!である)可能性もあるという点に気をつけてください。

ちなみに…テスト結果発表!!!(おまけ要素大)
- ・事前に学習している3種 :76.66% ※確実に OK, Inner point!と答えられたモノ
- ・学習すら行なっていない未知の1種 :100% ※どの点群にも含まれず、正しく「unknow(未知)」だと判断したモノ
この結果をみると、「曖昧」だと判断した23.34%のチェックと、「unknown(未知)」だと判断したモノがどんなやつかを確認し新しい分類種別を追加投入するかどうか考えれば良い事が分かりますね💡
3.4. 後日談:Tips
3.4.1. 画像の選定:サイズとの戦い
今回、どういったターゲット画像を扱うのか、その選定にとても苦労しました。
画像を扱いますのでライセンス問題ももちろんありますが、特に大変だったのがそもそも「素人では判断できない」という点から出発しているが故に、何をどう選べばいいのか、すんなり行きませんでした。素人ですから。
当初、データ数の多い種から集めようという事で「モンシロチョウ」もターゲットとしてある程度画像を収集し始めていました。が、ふとWikiを見ると「オオモンシロチョウとモンシロチョウの区別は難しく、大きさで区別する・・・」というような記実を発見。そうです、今回サイズに関する情報を一切入れておりません。そのため、どう頑張ってもオオモンシロチョウとモンシロチョウの区別をはじき出す事ができないんです。。。

[Lepidoptera collections]を確認すると、実は「大きさ」が分かるように計測用メジャーが添えられており、人間であれば(よく見ると)このサイズ感の違いを認識できるのですが、本ソリューションではメジャーや右側のタグなどは本質的では無い部分になるため、敢えてトリミング(該当箇所の削除)したものを扱っていました。「本質的では無い」とはどういう事かというと、この画像をそのまま学習に掛けてしまうと、「メジャーの数値、刻み」や「タグの有無、並び順」などの要素にマッピング(写像)が引っ張られる恐れがあるという事です。

では大きさの違いも含めて分類したい場合はどうすれば良いか?それは画像の撮影条件を予め揃えておく事です。 被写体までの距離、画角、位置など、できるだけ同条件で撮影されたものを取得する事で、「オオモンシロチョウとモンシロチョウの大きさの違い」を保持したまま学習に掛ける事が可能になります。
3.4.2. 補助マップ:画像AIの注視ポイント
詳しくは理論編の深い話になってしまうので省きますが、実は画像から抽出される「蝶の特徴情報」を可視化してみる事ができます。それぞれレイヤーごとにどこが反応しているのかを見て取れます。但し、注意点としては、これはあくまでも画像AIがどこを注視しているかであって、人間の直感と直結するかどうかは別の話になります。

4. 適応領域:想定および妄想
本ソリューションは以下のような方々に是非お使いいただきたいと考えております。
- 既に Problem を抱えている方
- "判別、識別、分別、区別、弁別、仕分け"といった作業をしていて、日々大変さ・辛さを感じている方
- 長時間、目を酷使した仕事・業務を抱えていて、何かしら解決の緒を見つけたい方 - 細かい違い・微妙な差のある画像を大量に持っている方で、「この違いって何?」を探求してみたい方
4.1. 既に Problem を抱えている作業
これに関しては製造業などの検品作業での適応を想定しております。
工業製品の検品作業
- 色、長さ、形状の違いや印字ミスなど、僅かな違いにより不良品を取り除く
- 異常の種類や異常度合いにより、後続の工程(修繕、部品交換、廃棄)へ適切に流す

4.2. 曖昧さへの探求・好奇心
これに関しては(できるかどうかは置いといて、ほぼ私個人の妄想強めですが)、アイデア次第でおもしろい事ができそうな気がしています。
空の探求
- 珍しい形の雲や空模様を収集し分類、その後の天気の変化と紐づけて学習
- 「積乱雲が出た後、急な雷が発生した」「乱層雲が発生した○○分後に雨が降り出した」など
- 天気予報の予測精度への貢献ができるのではないか?
- (そもそも個人的に、珍しそうな雲や空模様に遭遇した時、パシャ📸 っと撮って「珍しさ」や「雲に名前は付いているのか」などパッと分かるアプリがほしい。自称雨女は語る。)

車のクラッシュレベル
- 事故でつけた車の傷や経年劣化による錆びを破損レベルで分類
- 車両保険・補償の金額査定や車の買取査定に使ってみませんか?
- 感覚的な査定から視覚的判断基準確立へ!

5. 最後に
最後までお付き合いいただきありがとうございます。 今回は開発を担当したソリューションのご紹介となるため、ついつい力が入り過ぎて長編となってしまいましたが、いかがでしたでしょうか?読み疲れてはいないでしょうか?(筆者は大分書き疲れてしまいました…長編は良くないですね…) 謎に包まれた『[AIプロフェッショナルサービス]』のベールを1枚はがせたのではないでしょうか。
前段の理論編では本ソリューションの特徴を掻い摘んでご紹介し、続く実践編ではずぶの素人が昆虫学の分類にチャレンジしてみたら?を体感していただきました。また後日談としてTipsも記載させていただきました。
ポイントをいくつか挙げると
- 「曖昧さ」をうまく学習して可視化
- 可視化による「気づき」(変化やノイズ、分類ミスなど)
- 「未知」のモノへの柔軟性
全体を通してざっくりとした解説でしたが、少しでも「何ができるのか、どう使えそうか」の概観を掴んでいただけたのなら幸いです。(「ここの説明がとても分かり易くて課題解決の参考になりそう」「ここが難しかったのでもう少し説明してほしい」「長過ぎ!」などコメントがあればお寄せください。今後の励みになります。)
最後に本ソリューションの第一ターゲットとして製造業などの検品作業を挙げさせていただきましたが、アイデア次第でいろんな使い方ができると思いますので、「こういった領域でも使えますか?」「こういった使い方もできますか?」といったご要望やアイデアなどありましたら是非ご連絡ください!

Alibaba Cloudを始めてみましょう





