
 Edit on GitHub
Edit on GitHubElasticsearch 機械学習での異常検知体験
Elasticsearch 機械学習での異常検知体験
1、はじめに
Elasticsearchの検索と分析機能をさらに発展させたのが、Elasticsearchの「MachineLearning」機能と見なすことができ、時系列データの解析が可能です。ElasticsearchがサポートするMachineLearning機能は、分析するフィールドを定義する検出器を1つまたは複数含むmetricタスクを実行することによって、時系列データを自動的に分析することができます。これは時系列データにおける正常・異常を識別してくれます。
もともとElasticsearchが解決する機械学習に関する主要な問題の一つは「異常検出」です。「異常検出」は基本的に統計的な問題であり、入力データ分布の一般的な統計的属性から不規則性をマークすることで簡単に解決できます。それ以外の方法としては、クラスタリングに基づく異常検出やサポートベクトルマシンによる異常検出などの機械学習に基づく方法を用いて解決できます。
Elastic Stack(Elastic社が提供するコアプロダクト群Elasticsearch、Kibana、Beats、Logstashの総称、ELK Stackという愛称もある)が提供するMachineLearning機能が関係しているのは、Kibanaのデータ可視化ツール、Job管理、およびElasticsearchからの統計タスクの指標(metrics)集約です。また、Beatsを使ってデータを収集することもできます。例えば、Metricbeatを使用してシステムレベルのリソース使用状況統計情報を収集します。
AlibabaCloudでElasticsearchを使ってみたい場合は以下をご参照ください。
https://www.alibabacloud.com/cloud-tech/ja/product/57736.htm
2、異常とは
2-1. 周期的異常
下に時系列データを19個用意しました。AAL, AWEなど1つ1つが各航空会社の予約数を集計したものを時系列で表しています。ご覧ください。

まず緑色の線(つまりAAL社の予約数)を見てみます。明らかに2016年2月9日4時ごろのAAL社の予約数は他の日、時間帯より明らかに高いです。これは明らかに異常な状況といえます。しかし、この法則が毎週または毎月一定の時間帯で繰り返されているなら、このような状況も正常と言えるはずです。
もう一つの例としては、私たちは大都市に住んでいます。例えば、北京は金曜夜のピーク時、市内を出る車がとても多く、他の平日(月〜木)よりも明らかに多いです。もし一週間分だけの統計データを取ってみれば金曜だけ明らかに異常です。しかし毎週金曜がもれなくそうならこのようなピークも正常だといえます。この結論を出すには、長期的にデータを収集して分析する必要があります。
2-2. クラスタリングによる異常
先程用いた19個の時系列データ(各航空会社の予約数を集計)の別バージョン(別日に取得したもの)を見てみます。今度は19個のデータをグループとして眺めてみます。すると、ほとんどのデータが下部にかたまっているのが見てとれます。これを"normal"グループとします。逆に緑色の線(NKS)が1つだけ上部に外れて存在しているのが見てとれ、これを"anomalous"、つまり異常だと判断する事ができます。

まとめると、ほとんどのものが同じ挙動を示している中、ある一部のものがそこから外れた動きをしていると、異常だと判断する。
以上をまとめると、もし私達があることが異常と言ったら、それは以下の1つまたは2つに当てはまるはずです。
- データの動きが急に大きく変化するとき(周期的異常)
- あるデータとそれ以外のデータとが全く異なるとき(クラスタリングによる異常)
ElasticsearchのMachineLearning機能は、実際のデータに基づいて自動的に適切なデータモデル(データ分布)を選んでくれます。ほとんどの場合は一つ目のデータモデル(正規分布)です。そして他の確率イベントが発生した時に異常としてそれを検出します。

3、MachineLearning機能の異常検知について
MachineLearning機能ではElasticsearchに存在するデータを使用して、教師なしでデータモデルを構築します。新しいデータを事前に作成したデータモデルと比較して、データ中の異常または挙動を識別することにより、時系列データを自動的に解析することができます。ElasticsearchのMachineLearning機能では、以下のような機能があります。
- 異常検出
- 異常スコアリング(異常度合いを表す0から100までの点数で、高いほど異常だという意味)
これを使う前に、データの適用性を検証する必要があります。以下の三つのことを考えなければなりません。
- データは時系列データですか?(データの種類)
- どの項目・指標を重要な項目として分析したいですか?(分析対象・ターゲット)
- データの取得する期間はどれくらいですか?(データの期間)
実際には、MachineLearning機能のAPIを通じてあなたのデータを分析することができます。
データの異常を発見するためには、分析する項目・指標を定義する事が非常に重要なポイントです。例えば、以下のように定義する事が考えられます。
- 所定の期間に出力された「ログ数」
- 所定の期間に受信された「404応答値」
- 所定の期間に使用した「ディスク使用量」
- 顧客:例えばアプリケーション応答時間またはエラーカウント
- 利用可能性:例えば正常運行時間(MTBF)または平均メンテナンス時間(MTTR)
- 業務:例えば毎分注文数、売上、或いはアクティブユーザー数
MachineLearningのもう一つの重要な機能は、分析した時系列データの将来の動向を予測することです。Kibanaのインターフェースを使って予測する以外に、ElasticsearchもAPIインターフェースを提供しています。この機能を使うには、予測しようとする期間を指定する必要があります。
4、ElasticsearchのMachineLearning機能の構造
下図はMachineLearning機能のプロセスを簡略化して示しています。

さらにMachineLearningの処理を切り出したものが以下です。

このようなレイアウトはMLがオンライン(リアルタイム)で実行でき、新しいデータをどんどん分析し学習できることがポイントです。このプロセスはMLでも自動的に処理されますので、ユーザーはこのすべてを実現するために必要な複雑なプロセスを心配する必要はありません。
5、分析の種類
Kibana 7.0は4種類の「異常検出ジョブ」が用意されており、分析タスクを実行するために必要な設定情報などが含まれています。各異常検出ジョブは1つまたは複数の検出器を持っており、データ内の特定フィールドに対する分析を行います。実行できる分析の種類については以下です:
- Single-metric jobs:一つのインデックスフィールド(指標)でのみ分析します。例えばCPU使用率のみから分析するとき。
- Multi-metric jobs:複数のインデックスフィールド(指標)に対してデータ分析を実行しますが、各フィールドはそれぞれ分析を行います。例えば、CPU使用率とディスク使用量など同時に分析しそれらの関係性(関連するか)をみたいときなど。
- Advianced jobs:複数のインデックスフィールド(指標)に対してデータ分析を実行できます。Multi-metric jobsとの違いは、検出器と影響フィールドを細かく設定できます。(完全なカスタマイズ)
- Population jobs:クラスタリングによる異常検知を実行するもので、同じ挙動をする多くのデータの中から、ある一部の外れた動きを検出します。
今回は、single-metric jobsを使用した例を示します。
6、single-metricで異常検知体験
今回扱うデータは公開されているNABデータの一部(file:art_daily_flatmiddle.csv)を使います。
https://github.com/numenta/NAB/blob/master/data/artificialWithAnomaly/art_daily_flatmiddle.csv
基本的に、single-metric jobでは、分析検出器としてインデックスフィールドを一つだけを指定できます。ここでは、NABデータを用いて、single-metric jobの手順を説明します。
1、データのインポートとIndexの作成
早速データをインポートします。MachineLearningの「Data Visualizer」より、直接csvフォマートファイル「art_daily_flatmiddle.csv」をElasticsearchにインポートします。すると自動的にIndex「art_daily_flatmiddle」が作成されます。

では実際にIndex「art_daily_flatmiddle」を確認してみましょう。以下のようにインポートしたNABデータがかくにん出来ます。

2、 single-metricのタスクを作成
左側のツールバーのMachine Learningボタンをクリックして、Job Managementタブをクリックすると以下のように表示されます。右側のCreate new jobをクリックすると新しいタスクが作成されます。

下の画面でIndex「art_daily_flatmiddle」を選択します。
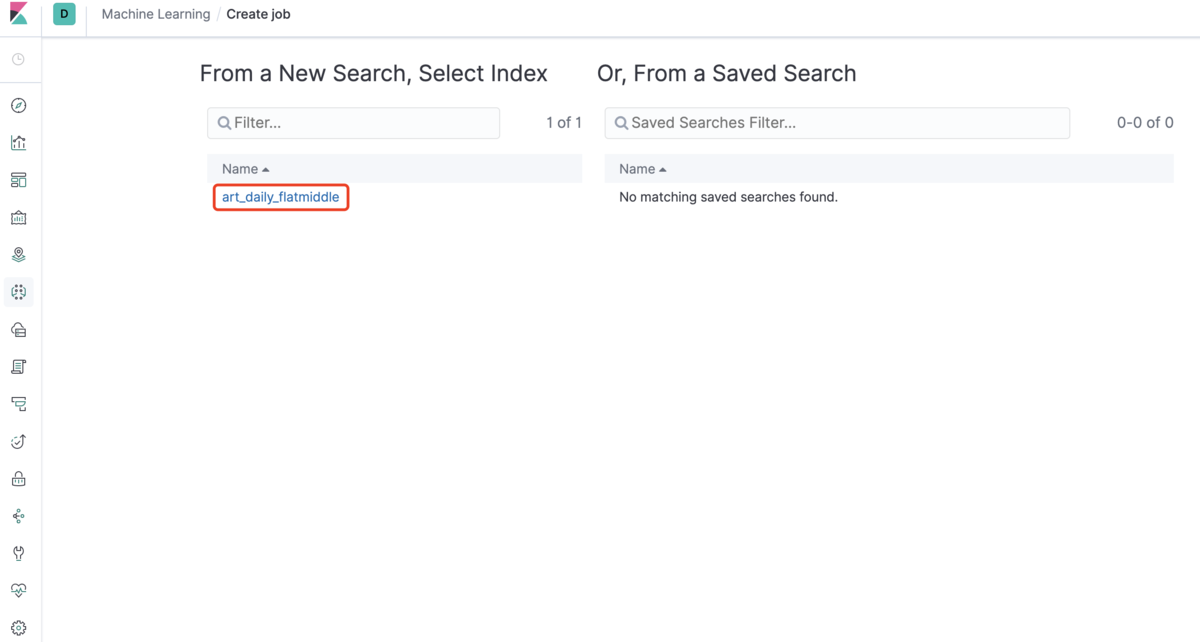
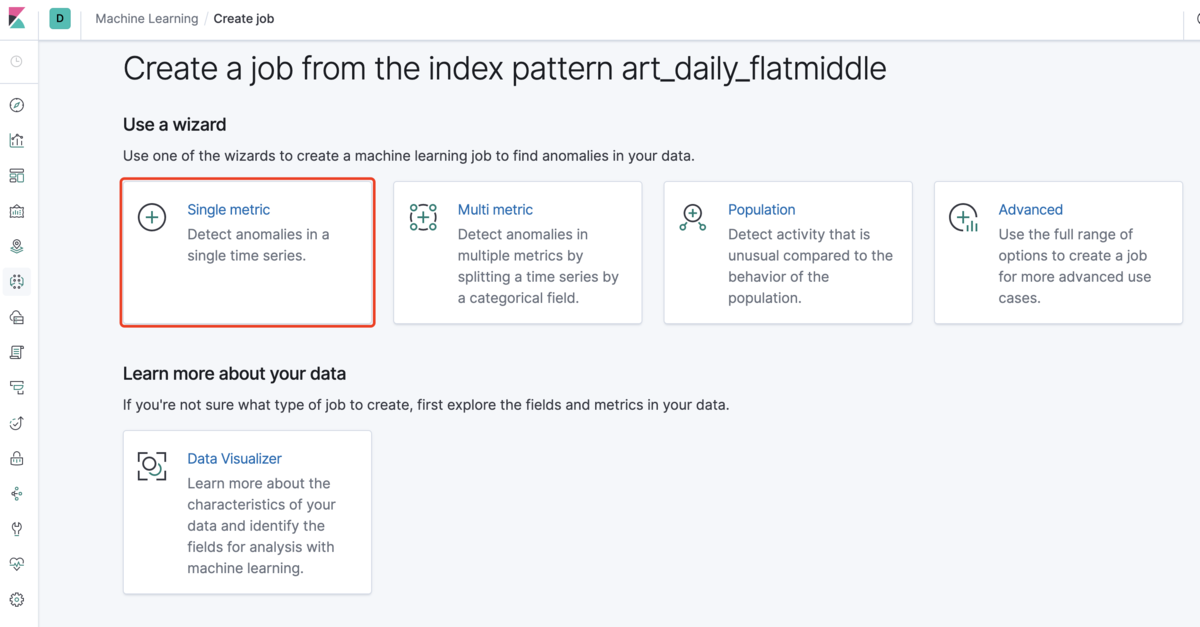
次は「Single metric」を選択します。
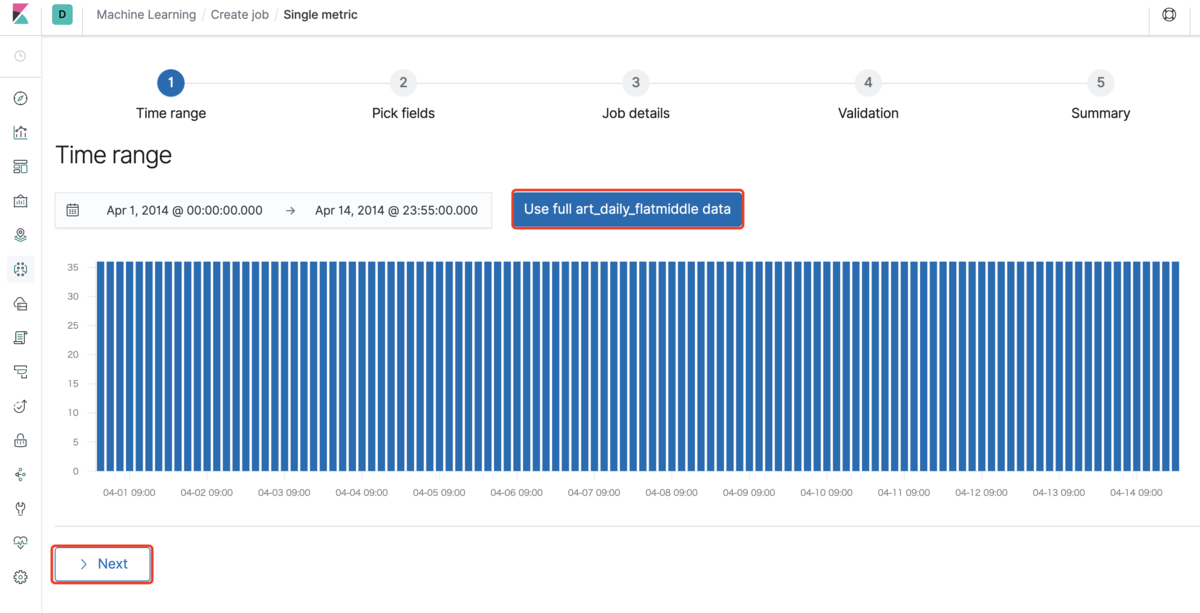
次はTime range(どの期間を異常検出の対象にするか)に「Use full art_daily_flatmiddle data」を選択し、「Next」をクリックします。
・集約の選択
single-metric jobはデータ集約の種類(sum, max, min, mean, median等)を使用しなければならない。NABデータのvalueフィールドのMean集約を選択します。これも前に話した指標です。私たちの目的はvalueの平均に異常があるかどうかを確認することです。
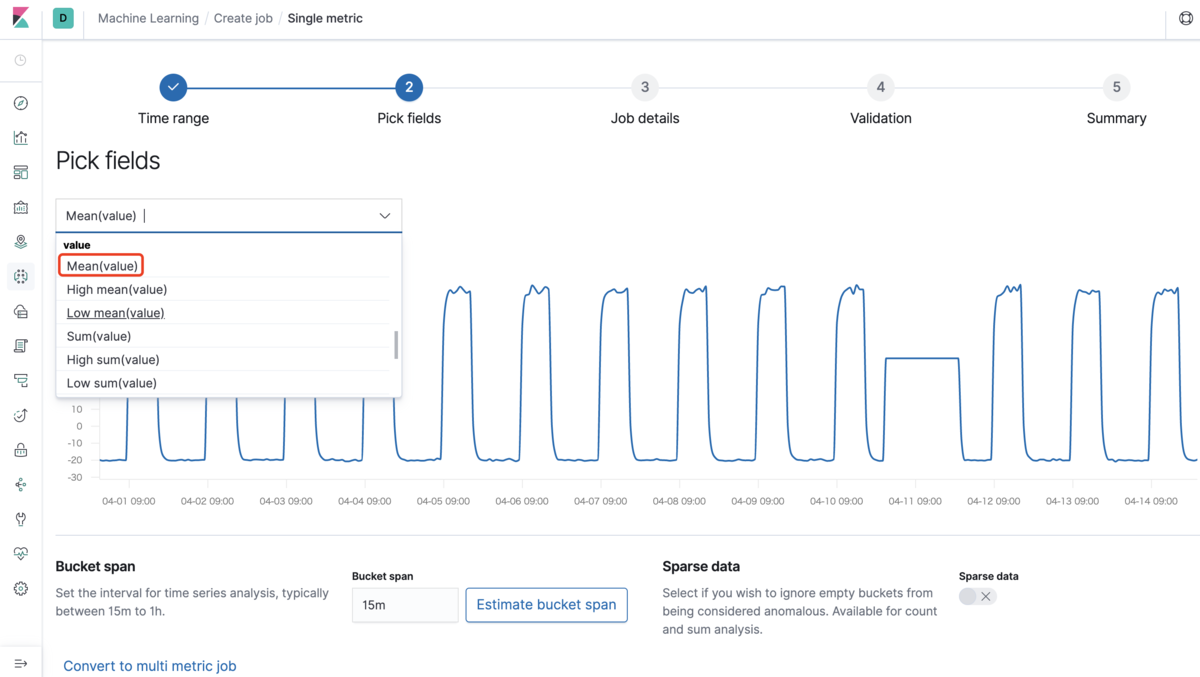
続いて、Bucket span(どのくらいの時間をひと区切りとして分析するか)を15minで指定し、Nextをクリックします。
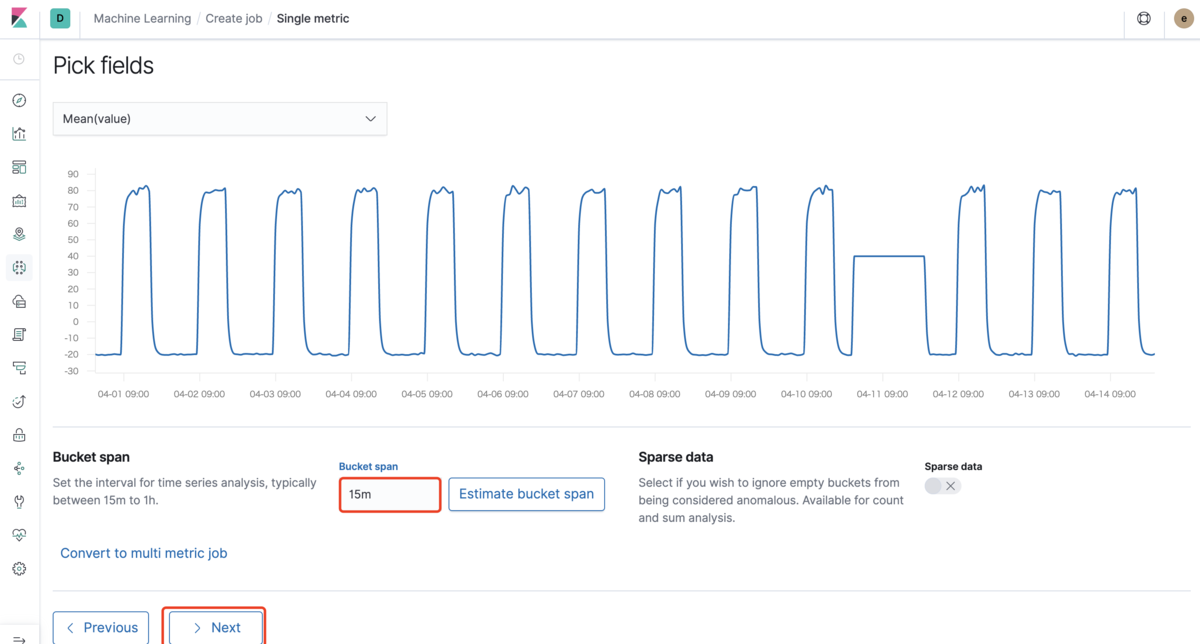
Job IDとGroupsを入力して、Nextをクリックします。
上にValidation情報(データがsingle-metric jobの適応可能かどうかの検証)が表示されます。このステップでエラーがあったら、エラーメッセージが赤文字で表示されます。上にすべてが良いと表示されます。次に、Nextボタンをクリックします。
次で「Create job」をクリックします。
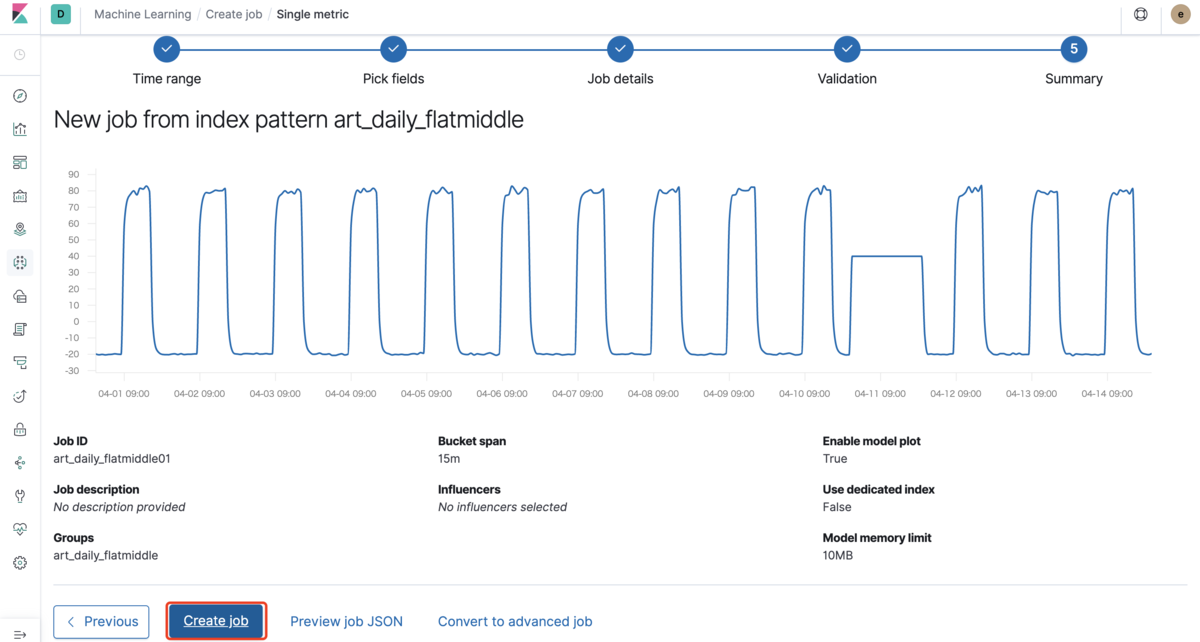
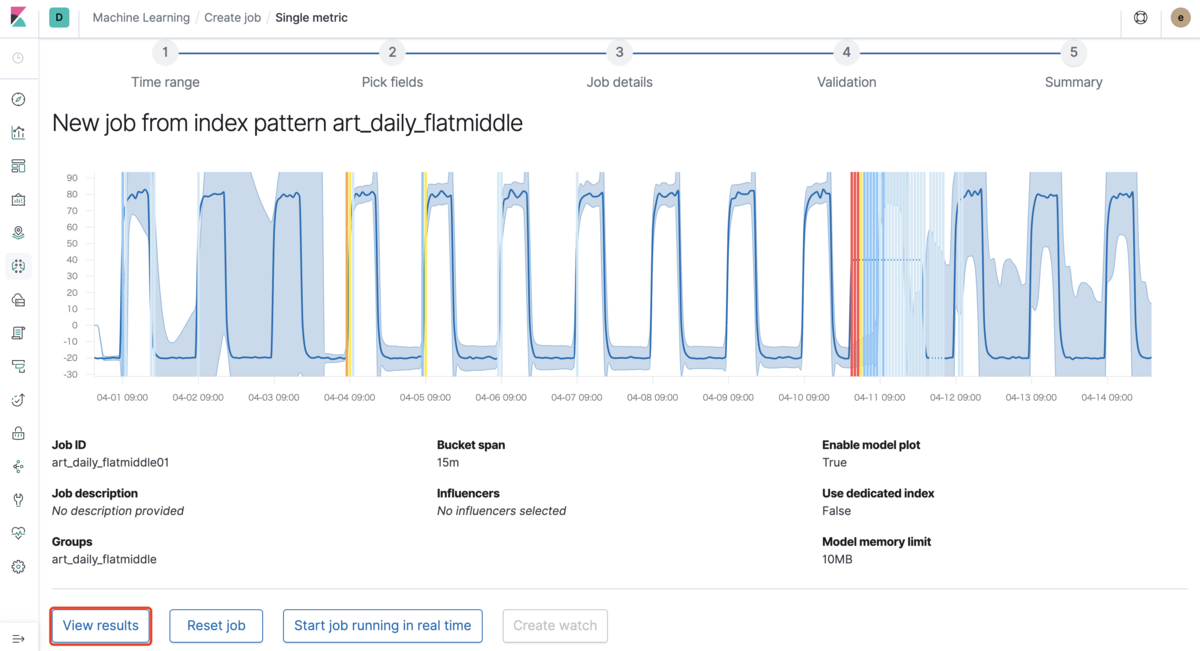
次で「View results」を選択します。
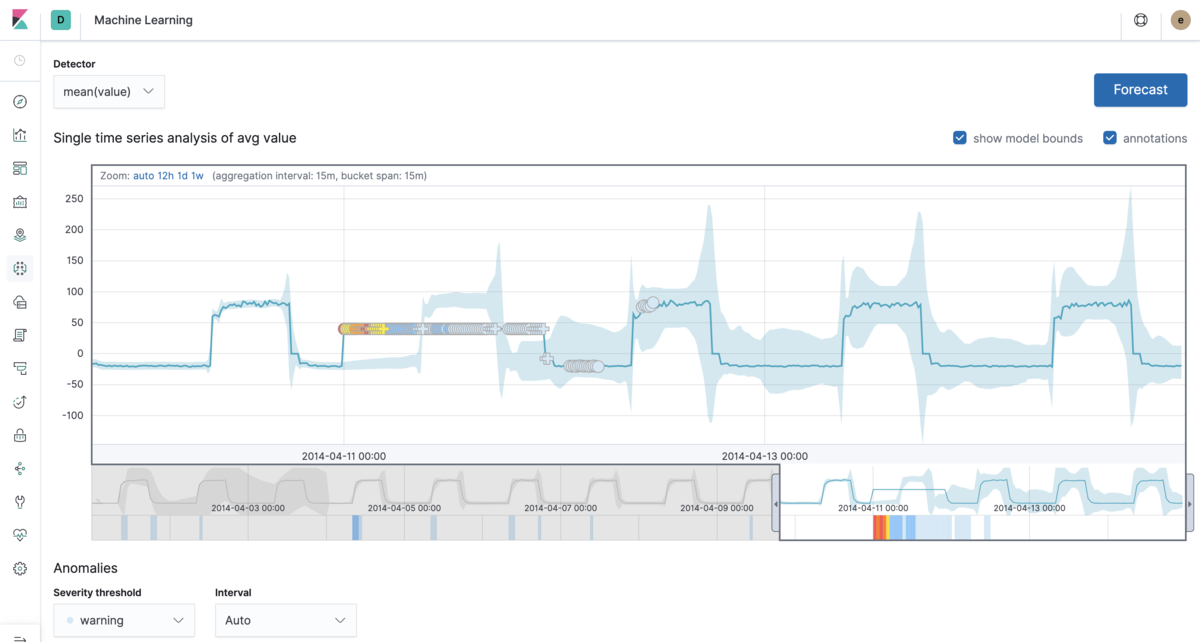
上図では、最初の部分では「正常な状態」のデータを学習しながらモデルを構築して行きます。しばらくすると正常な状態から外れた挙動、つまり異常な状況を検知できました。
3、結果の説明
おめでとうございます。もうsingle-metric jobのタスクを作成しました。次のAnomaliesをクリックして見てみます。
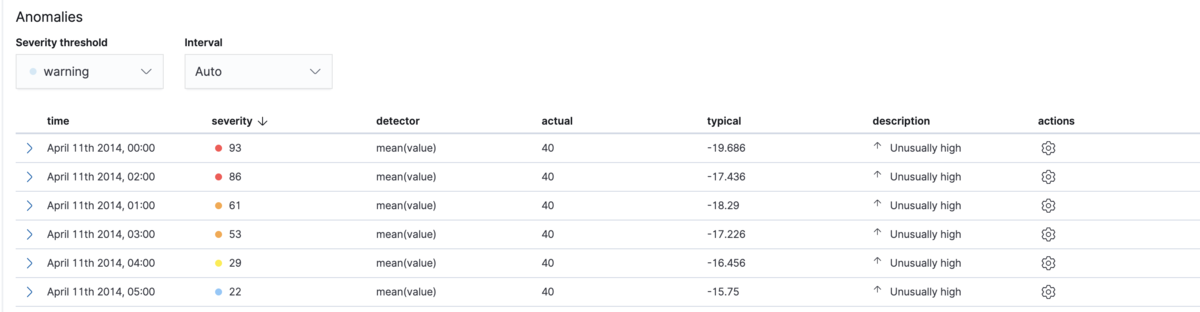
上図のように各色で異常スコアを表しています。
- Warning(blue):異常スコアが25以下です。
- Minor(yellow):異常スコアは25と50の間です。
- Major(orange):異常スコアは50と75の間です。
- Critical(red):異常スコアは75と100の間です。
一番上の「April 11th 2014, 00:00」をクリックしてみると:
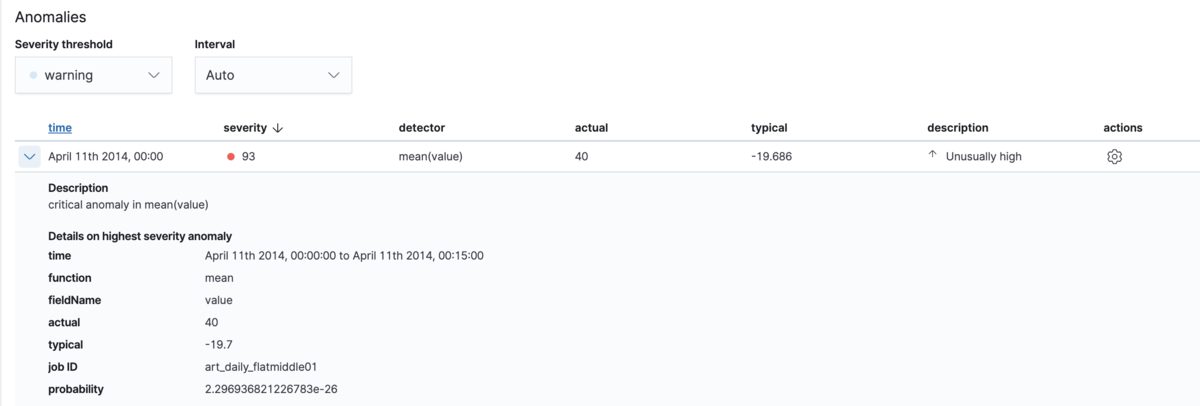
single-metric jobによって予測される値は-19.7ですが、実際の値は40です。これは明らかに異常です。
7、終わりに
以上でElasticsearchのMachine Learning機能で異常検知してみました。single-metric jobだけですが、異常の定義からElasticSearchを使った異常検出までの流れを説明しました。
もっと試したい方は是非NABデータを使ってmulti-metric jobs も試してください。


Alibaba Cloudを始めてみましょう





